# Utilities
from pathlib import Path
import re
import traceback
from urllib.request import urlretrieve
import time
# Display
from IPython.display import HTML
from html import escape
# Computation Libraries
import numpy as np
from sentence_transformers import SentenceTransformer
data_dir = Path('data')
data_dir.mkdir(exist_ok=True)
model_dir = Path('models')
model_dir.mkdir(exist_ok=True)Exporting Nomic’s Mixture of Experts model to ONNX
onnx
Sparse mixture of experts models can contain the parameters and information of a large model but run as fast as a much smaller model by only multiplying some of the parameters, depending on the input, on every prediciton. ONNX (Open Neural Network Exchange) is a way to represent models independent of the framework it was trained in, making it easy to serve the model in a wide variety of languages using a run-time like onnxruntime. Unfortunately onnx doesn’t have many tools for running conditional computations and so exporting a Mixture of Experts model to ONNX model isn’t always easy.
Nomic AI recently released a very good multilingual open source mixture-of-experts embedding model, nomic-embed-text-v2-moe. This article will go through one way to exporting this model to ONNX, working through the problems that arise on the way.
Note
This document is an executable Jupyter notebook and the soure code is available
Before we get into the details I want to give some motivation of why you might want to do this; if you’re already motivated then skip ahead to the first ONNX export section.
Motivation
Embedding models are really useful for “semantic search”, that matches the meaning but not the exact wording of a query, making them a good complement to text matching algorithms like BM25.
To get things set up import some libraries including Sentence Transformers which makes it easy to use the embedding models.
Data
Any human readable text data is a good candidate for embedding; as an example we will use Captain Cook’s Journal During His First Voyage Round the World from Project Gutenberg.
text_url = 'https://www.gutenberg.org/cache/epub/8106/pg8106.txt'
text_path = data_dir / text_url.split('/')[-1]
if not text_path.exists():
urlretrieve(text_url, text_path)
with open(text_path, 'rt') as f:
full_text = f.read()The full text is split into individual passages that can be searched.
passages = [p for p in
full_text.split('\n\n') # All paragraphs
[472:1989] # in main body text
if not p.startswith('[') # except editor comments
and not (p == p.upper()) # and chapter headings
and len(p) > 35 # and very short paragraphs
]
len(passages)1281The first few passages show the style of the text is succinct updates of what happened each day. There’s a lot of details about the weather, which I suppose is very important on a sea voyage.
for passage in passages[:5]:
print(passage)
print()RIVER THAMES, Friday, May 27th, to Friday, July 29th. Moderate and fair
weather; at 11 a.m. hoisted the Pendant, and took charge of the Ship,
agreeable to my Commission of the 25th instant, she lying in the Bason in
Deptford Yard. From this day to the 21st of July we were constantly
employed in fitting the Ship, taking on board Stores and Provisions, etc.
The same day we sailed from Deptford and anchored in Gallions reach, were
we remained until the 30th. The transactions of Each Day, both while we
lay here and at Deptford, are inserted in the Log Book, and as they
contain nothing but common Occurrences, it was thought not necessary to
insert them here.
July 30th to August 7th. Saturday, July 30th, Weighed from Gallions, and
made sail down the River, the same day Anchored at Gravesend, and the
next Morning weighed from thence, and at
Noon Anchored at the Buoy of the Fairway. On Wednesday, 3rd of August,
Anchored in the Downs in 9 fathoms of water, Deal Castle North-West by
West. On Sunday, 7th, I joined the Ship, discharged the Pilot, and the
next day saild for Plymouth.
Monday, 8th. Fresh Breezes and Cloudy weather the most part of these 24
hours. At 10 a.m. weighed and came to sail; at Noon the South Foreland
bore North-East 1/2 North, distant 6 or 7 Miles. Wind West by North,
North-West.
Tuesday, 9th. Gentle breezes and Cloudy weather. At 7 p.m. the Tide being
against us, Anchored in 13 fathoms of Water; Dungeness South-West by
West. At 11 a.m. Weighed and made Sail down Channel; at Noon, Beachy
Head, North by East 1/2 East, distant 6 Leagues, Latitude observed 50
degrees 30 minutes North. Wind North-West to North.
Wednesday, 10th. Variable: light Airs and Clear weather. At 8 p.m. Beachy
Head North-East by East, distant 4 Leagues, and at 8 a.m. it bore
North-East by North, 9 Leagues. Found the Variation of the Compass to be
23 degrees West; at Noon the Isle of Wight North-West by North. Wind West
by North, North-East by East.
Embedding the texts
Text embedding models work by mapping each text into a vector in a high dimensional vector space, in such a way that queries end up close to relevant documents. The model nomic-embed-v2-moe is a model that has been explicitly trained to do this and, according to its report, gets good scores on semantic search benchmarks like BEIR (which covers English retrieval across multiple domains) and MIRACL (which covers search over Wikipedia in multiple languages).
model_name = 'nomic-ai/nomic-embed-text-v2-moe'
revision = '1066b6599d099fbb93dfcb64f9c37a7c9e503e85'
st_model = SentenceTransformer(model_name,
trust_remote_code=True,
revision=revision,
device='cpu')/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/7710840340a098cfb869c4f65e87cf2b1b70caca/modeling_hf_nomic_bert.py:1634: UserWarning: Install Nomic's megablocks fork for better speed: `pip install git+https://github.com/nomic-ai/megablocks.git`The model has a pre-determined maximum length in tokens, which are the smallest pieces of text the model recognises. Actually this model can handle sequences as long as you can fit into memory, but the embeddin training was only done to 512 tokens. Any text longer than this will be truncated from the right.
st_model.max_seq_length512Sentence Transformers can then convert all the passages to embeddings, in this case of dimension 768.
embeddings = st_model.encode(
passages,
prompt_name="passage", # Embed these as passages to search
normalize_embeddings=True, # Normalise the vectors to unit length
)
embeddings.shape(1281, 768)Search
To run a search the query needs to be embedded with the same model, and then we need to find the closest passages in the embedding space. This model works with cosine similarity, and since we’ve normalised the embeddings, is just the dot product. If the index contained millions of passages it would make sense to use an approximate nearest neighbours method to search quickly, but with a thousand passages it’s quick enough to calculate the distance to every passage.
def search(query, k, embeddings=embeddings, st_model=st_model):
query_embedding = st_model.encode(
query,
prompt_name="query", # Encode as a query
normalize_embeddings=True, # Unit normalize
)
scores = embeddings @ query_embedding # Calculate the index
idxs = np.argsort(-scores) # Indices in descending distance order
return [passages[idx] for idx in idxs[:k]]As an example the passages closest to storm; all but the second last are related to stormy weather, but only the first and the last contain the string “Storm”.
for passage in search("storm", k=5):
print(passage)
print()Thursday, 2nd. Winds and weather as yesterday, or rather more Stormy; we
have now no Success in the Sein fishing, hardly getting above 20 or 30
pounds a day.
Sunday, 9th. First and latter parts ditto weather, middle squally with
rain. In the P.M. sent on shore a Boat load of empty casks, and at the
same time went myself in order to forward the things we wanted, and in
the evening sent on board the new Pump, with some other stores that were
immediately wanting.
Monday, 22nd, which was usher'd in with thick Cloudy weather, and
Excessive hard Showers of rain and very much Thunder and Lightning, which
Continued the Greater part of the day.
Saturday, 4th. Little wind and pleasant weather. At 6 A.M. the Portland
made the Signal to unmoor, and at Noon to Weigh, at which time the Ships
began to get under Sail. Wind Ditto. At noon at Anchor in St. Helena
Road.
Wednesday, 18th. All the Middle and Latter parts of this day it blow'd
very strong from the South-South-West and South-West, attended with Snow,
Hail and Rain, and brought such a Sea into the Bay, which rose the Surf
to such a Height that no Boat could land. The same Stormy weather and
Surf continued all
As another example we could ask a natural language question like “What food did they eat?” and get passages talking about food without containing the word “eat” or “food”.
for passage in search("What food did they eat?", k=3):
print(passage)
print()Monday, 7th. From this day till Monday 14th we were employ'd wooding and
watering, being frequently interrupted by heavy rains. Having now
compleated both we hoisted in the Long boat, and made ready to put to
Sea, having on board a pretty good stock of refreshments, which we
purchased of the natives, such as Turtle, Fowls, Fish, two species of
Deer, one about as big as a small sheep, the other no bigger than a
Rabbit; both sorts eat very well, but are only for present use, as they
seldom lived above 24 hours in our possession. We likewise got fruit of
several sorts, such as Cocoa Nutts, plantains, Limes, etc. The Trade on
our part was carried on chiefly with money (Spanish Dollars); the natives
set but little value upon any thing else. Such of our people as had not
this Article traded with Old Shirts, etc., at a great disadvantage.
In the Article of Food these People have no great Variety; Fern roots,
Dogs, Fish, and wild fowl is their Chief diet, for Cocos, Yams, and Sweet
Potatoes is not Cultivated every where. They dress their Victuals in the
same Manner as the people in the South Sea Islands; that is, dogs and
Large fish they bake in a hole in the ground, and small fish, birds, and
Shell fish, etc., they broil on the fire. Fern roots they likewise heat
over the fire, then beat them out flat upon a stone with a wooden Mallet;
after this they are fit for Eating, in the doing of which they suck out
the Moist and Glutinous part, and Spit out the Fibrous parts. These ferns
are much like, if not the same as, the mountain ferns in England.
The produce of this Island is Bread Fruit, Cocoa Nuts, Bonanoes,
Plantains, a fruit like an Apple, sweet Potatoes, Yams, a Fruit known by
the name of Eag Melloa, and reck'ned most delicious; Sugar Cane which the
inhabitants eat raw; a root of the Salop kind, called by the inhabitants
Pea; the root also of a plant called Ether; and a fruit in a pod like a
Kidney bean, which when roasted eats like a Chestnut, and is called Ahee;
the fruit of a Tree which they call Wharra, something like a Pine Apple;
the fruit of a Tree called by them Nano; the roots of a Fern and the
roots of a plant called Thive. All these Articles the Earth almost
Spontaniously produces, or, at least, they are raised with very little
Labour. In the Article of food these people may almost be said to be
exempt from the Curse of our Forefathers, scarcely can it be said that
they Earn their bread with the sweat of their brow; benevolent Nature
hath not only Supply'd them with necessarys, but with abundance of
Superfluities. The Sea coast supplies them with vast Variety of most
Excellent fish, but these they get not without some Trouble and
Perseverance. Fish seems to be one of their greatest Luxuries, and they
Eat it either raw or Dressed and seem to relish it one way as well as the
other. Not only fish but almost everything that comes out of the Sea is
Eat and Esteem'd by these People; Shell Fish, Lobsters, Crabs, and even
sea insects, and what is commonly called blubbers of many kinds, conduce
to their support.
As a final example the passages can be searched to find the “worst conditions” of the trip, and the resulting passages sound pretty bad.
for passage in search("worst conditions", k=3):
print(passage)
print()Friday, 26th. Set up the Ship's Tent for the reception of the Ship's
Company, several of them begin to be taken ill, owing, as I suppose, to
the extream hot weather.
Sunday, 14th. Wind Westerly, gentle breezes. In the P.M. got all the Sick
on board, many of whom are yet in a very bad state of health; 3 died
here, but this loss was made up by the opportunity we had of compleating
our full complement. In the morning unmoor'd and got ready for Sailing.
Be this as it will, Batavia is certainly a place that Europeans need not
covet to go to; but if necessity obliges them, they will do well to make
their stay as short as possible, otherwise they will soon feel the
effects of the unwholesome air of Batavia, which, I firmly believe, is
the Death of more Europeans than any other place upon the Globe of the
same extent. Such, at least, is my opinion of it, which is founded on
facts. We came in here with as healthy a Ship's Company as need go to
Sea, and after a stay of not quite 3 months left it in the condition of
an Hospital Ship, besides the loss of 7 men; and yet all the Dutch
Captains I had an opportunity to converse with said that we had been very
lucky, and wondered that we had not lost half our people in that time.*
(* Batavia bears an evil reputation for health to this day; but it must
be remembered that the Endeavour lay there during the rainy or most
unhealthy season.)
Now suppose we wanted to put this into production in a language other than Python; we could use a binding to Torch’s C++ API which brings in some complexity in porting the model, or we could export it to ONNX and use something like onnxruntime to serve it.
Exporting to ONNX
Attempt 1: Sentence Transformers (Optimum)
The first obvious thing to try is to use SentenceTransformer’s ONNX export, which uses HuggingFace Optimum under the hood.
try:
onnx_model = SentenceTransformer(model_name,
trust_remote_code=True,
revision=revision,
backend='onnx')
except ValueError as e:
print('Error: %s' % e)No 'model.onnx' found in 'nomic-ai/nomic-embed-text-v2-moe'. Exporting the model to ONNX.Error: Trying to export a nomic-bert model, that is a custom or unsupported architecture, but no custom onnx configuration was passed as `custom_onnx_configs`. Please refer to https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#custom-export-of-transformers-models for an example on how to export custom models. Please open an issue at https://github.com/huggingface/optimum/issues if you would like the model type nomic-bert to be supported natively in the ONNX export.Unfortunately it only works with a short list of specifically supported architectures, and Nomic’s models are not on that list.
Embedding with Transformers
PyTorch can export models to ONNX directly so we can try to use that insead, but first we need to unwrap the SentenceTransformer abstraction and look at what’s going on under the hood. In particular we’ll directly use huggingface transformers library to load the model.
from transformers import AutoModel, AutoTokenizer
import torchWe can load the model weights and tokenizer (SentenceTransformers wraps both of these); as before we have a maximum length of 512.
model = AutoModel.from_pretrained(model_name,
trust_remote_code=True,
revision=revision)
tokenizer = AutoTokenizer.from_pretrained(model_name,
trust_remote_code=True,
revision=revision)
tokenizer.model_max_length512Then to embed the following queries:
queries = ["What food did they eat?", "thunderstorms"]
queries['What food did they eat?', 'thunderstorms']In SentenceTransformers we need to run:
st_embeddings = st_model.encode(queries,
prompt_name="query",
normalize_embeddings=True,
convert_to_tensor=True)
st_embeddings.shapetorch.Size([2, 768])The prompt_name corresponds to a task-specific prefix that the model was trained on so that it knows whether the input is a document or a query. We can find out what this is by reading the technical report checking the config_sentence_transformers.json or looking in the .prompts:
st_model.prompts{'query': 'search_query: ',
'passage': 'search_document: ',
'Classification': 'classification: ',
'MultilabelClassification': 'classification: ',
'Clustering': 'clustering: ',
'PairClassification': 'classification: ',
'STS': 'classification: ',
'Summarization': 'classification: ',
'Speed': 'search_document: '}To get the correct embeddings search_query: needs to be prefixed to each query:
texts = ["search_query: " + query for query in queries]
texts['search_query: What food did they eat?', 'search_query: thunderstorms']Then the tokenizer is used to convert the text into a series of numerical ids that the model knows how to handle:
tokens = tokenizer(texts,
padding=True,
return_tensors='pt')
input_ids = tokens['input_ids']
input_idstensor([[ 0, 33938, 454, 944, 1294, 12, 4865, 15381, 6777,
1836, 73203, 32, 2],
[ 0, 33938, 454, 944, 1294, 12, 4911, 7944, 129857,
7, 2, 1, 1]])The padding=True was necessary to get a rectangular array (which Torch requires) instead of a jagged array by inserting pad tokens. To make sure the padding doesn’t change the answer there is an attention_mask that is 0 on all the padding tokens.
attention_mask = tokens['attention_mask']
attention_masktensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]])To see this explicitly let’s write a little function to show the individual tokens, their ids and the attention mask.
id_lookup = {v:k for k,v in tokenizer.vocab.items()}
def html_row(items: list[str], header=None) -> str:
"""Return html to show a row of items
If items is empty return empty string"""
if not items:
return ""
row = ''.join(["<td>" + escape(item) + "</td>" for item in items])
header = "<th>" + escape(header) + "</th>" if header is not None else ""
return "<tr>" + header + row + "</tr>"
def html_tokens(token_ids, formatters=None, id_lookup=id_lookup, **kwargs):
if formatters is None:
formatters = {}
token_id_str = [str(t.item()) for t in token_ids]
tokens = [id_lookup[t.item()] for t in token_ids]
extra_rows = []
for kw, tensor in kwargs.items():
formatter = formatters.get(kw, lambda x: str(x.item()))
extra_rows.append(html_row([formatter(t) for t in tensor], header=kw))
html_extra_rows = '\n'.join(extra_rows)
return f"""<table>
{html_row(tokens, "Token")}
{html_row(token_id_str, "ID")}
{html_extra_rows}
</table>"""Here’s the first query; notice that the first six tokens just encode the start token <s> and the query prompt. The attention mask is all 1 since they are all contentful tokens.
HTML(html_tokens(input_ids[0], AttentionMask=attention_mask[0]))| Token | <s> | ▁search | _ | que | ry | : | ▁What | ▁food | ▁did | ▁they | ▁eat | ? | </s> |
| ID | 0 | 33938 | 454 | 944 | 1294 | 12 | 4865 | 15381 | 6777 | 1836 | 73203 | 32 | 2 |
| AttentionMask | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
For the second query the last two tokens are special <pad> tokens that indicate it is past the end of the string, and the attention_mask is zero on these tokens.
HTML(html_tokens(input_ids[1], AttentionMask=attention_mask[1]))| Token | <s> | ▁search | _ | que | ry | : | ▁thu | nder | storm | s | </s> | <pad> | <pad> |
| ID | 0 | 33938 | 454 | 944 | 1294 | 12 | 4911 | 7944 | 129857 | 7 | 2 | 1 | 1 |
| AttentionMask | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
When the input_ids are put through the model we get an output 768-dimensional embedding for each token of the input.
with torch.inference_mode():
model_output = model(input_ids, attention_mask)
model_outputBaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=tensor([[[ 0.6144, 0.5655, 0.0732, ..., -0.1502, -0.3853, 0.5019],
[ 0.8870, 0.3930, -0.5521, ..., 0.2549, -0.7876, 1.1182],
[ 0.5724, 1.2011, -0.0462, ..., -0.1216, 0.3720, 1.4457],
...,
[ 0.4333, 0.1363, -0.1364, ..., 0.1581, -0.2119, -0.2602],
[ 0.7541, 0.9300, -0.1350, ..., -0.2900, -0.2110, 1.2073],
[ 0.6275, 0.6497, -0.0373, ..., -0.3004, -0.5346, 0.6286]],
[[ 0.4435, 0.0964, 0.3501, ..., -0.0903, -0.3210, 0.1285],
[ 1.0036, 0.2632, 0.2588, ..., -0.8356, -0.4994, 1.2230],
[ 0.8230, 0.5872, 0.2623, ..., -0.9592, 0.1922, 1.6073],
...,
[ 0.4239, -0.0415, -0.0790, ..., -0.7102, -0.3594, 0.3975],
[ 0.5177, 0.0198, -0.2920, ..., 0.3866, 0.0566, 0.3639],
[ 0.4159, 0.0270, -0.2100, ..., 0.2291, 0.1682, 0.2517]]]), pooler_output=None, hidden_states=None, past_key_values=None, attentions=None, cross_attentions=None)We had 2 examples of 13 tokens, ans so the output is 2 x 13 x 768.
last_hidden_state = model_output[0]
last_hidden_state.shapetorch.Size([2, 13, 768])To get a single embedding we need some way of “pooling” the embeddings from the different tokens. A common method, used by this model, is “mean pooling” which averages the scores over all the embeddings. Then when we unit normalise it we get the same result as we did with Sentence Transformers.
mean_pooled = last_hidden_state[0].mean(dim=0)
embedding = mean_pooled / ((mean_pooled ** 2).sum() ** 0.5)
assert torch.allclose(st_embeddings[0], embedding)We need to be a bit more careful with mean pooling the second example; any amount of padding should not change the final answer. This can be done by only calculating the average over the tokens where attention_mask is 1:
# Set to zero all hidden states where attention_mask is 0
masked_last_hidden_state = last_hidden_state[1] * attention_mask[1].unsqueeze(-1)
# Calculate the total numerator for the average
numerator = masked_last_hidden_state.sum(dim=0)
# Calculate the denominator, the number of tokens where attention_mask is 1
denominator = attention_mask[1].sum()
# Mean pool
mean_pooled = numerator / denominator
# Unit normalise
embedding = mean_pooled / ((mean_pooled ** 2).sum() ** 0.5)
assert torch.allclose(st_embeddings[1], embedding)Let’s wrap this up in a single function:
from torch.nn import functional as F
def mean_pooling(token_embeddings, # [B,L,D]
attention_mask, # [B,L]
normalize: bool = True,
): # -> [B,D]
# [B, L, 1]
attention_mask_expanded = attention_mask.unsqueeze(-1)
# [B, D]
numerator = (token_embeddings * attention_mask_expanded).sum(dim=1)
# [B, 1]
denominator = attention_mask_expanded.sum(axis=1)
embeddings = numerator / denominator
if normalize:
embeddings = F.normalize(embeddings)
return embeddings
Which gives the same result as SentenceTransformers
embeddings = mean_pooling(last_hidden_state, attention_mask)
assert torch.allclose(embeddings, st_embeddings)Attempt 2: Torch (JIT Trace)
Following the PyTorch ONNX export tutorial we can export the model which works, but with a bunch of warnings, which we’ll blithely ignore for now.
onnx_path = model_dir / 'nomic-v2-moe.onnx'
torch.onnx.export(model.eval(),
(input_ids, attention_mask),
onnx_path,
input_names = ['input_ids', 'attention_mask'],
dynamic_axes = {'input_ids': {0: 'batch', 1: 'sequence_length'},
'attention_mask': {0: 'batch', 1: 'sequence_length'},
},
dynamo=False,
)/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/7710840340a098cfb869c4f65e87cf2b1b70caca/modeling_hf_nomic_bert.py:1386: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/7710840340a098cfb869c4f65e87cf2b1b70caca/modeling_hf_nomic_bert.py:1339: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/7710840340a098cfb869c4f65e87cf2b1b70caca/modeling_hf_nomic_bert.py:1272: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/7710840340a098cfb869c4f65e87cf2b1b70caca/modeling_hf_nomic_bert.py:1212: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/7710840340a098cfb869c4f65e87cf2b1b70caca/modeling_hf_nomic_bert.py:1215: TracerWarning: Converting a tensor to a Python list might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/7710840340a098cfb869c4f65e87cf2b1b70caca/modeling_hf_nomic_bert.py:1216: TracerWarning: Converting a tensor to a Python list might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
/micromamba/envs/onnx-moe/lib/python3.11/site-packages/torch/onnx/symbolic_opset9.py:5350: UserWarning: Exporting aten::index operator of advanced indexing in opset 17 is achieved by combination of multiple ONNX operators, including Reshape, Transpose, Concat, and Gather. If indices include negative values, the exported graph will produce incorrect results.
/micromamba/envs/onnx-moe/lib/python3.11/site-packages/torch/onnx/symbolic_opset9.py:6040: UserWarning: Warning: ONNX export does not support duplicated values in 'index' field, this will cause the ONNX model to be incorrect.ONNX Inference
Now we’ve exported the ONNX model we cal load it in with ONNX runtime:
import onnxruntime
ort_session = onnxruntime.InferenceSession(
onnx_path, providers=["CPUExecutionProvider"]
)And when we run inference we get a very close result to running the model with PyTorch:
output = ort_session.run(None, {"input_ids": input_ids.numpy(), "attention_mask": attention_mask.numpy()})[0]
assert np.allclose(output, last_hidden_state, atol=1e-5)But if we try to run any other query something bad happens:
tokens = tokenizer(['search_query: weather'])
try:
output = ort_session.run(None, {"input_ids": tokens['input_ids'], "attention_mask": tokens['attention_mask']})[0]
except Exception as e:
print(e)[ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Non-zero status code returned while running Expand node. Name:'/encoder/layers.1/mlp/experts/Expand_1' Status Message: invalid expand shape2025-06-13 22:37:41.194455682 [E:onnxruntime:, sequential_executor.cc:572 ExecuteKernel] Non-zero status code returned while running Expand node. Name:'/encoder/layers.1/mlp/experts/Expand_1' Status Message: invalid expand shapeWhat happened is that when Torch exported the model with JIT Trace it captured the control flow with how the model executed on that example. If there’s conditional execution (which the warnings were telling us about) then a different output could raise an error, or succesfully return the wrong answer.
The newer Torch Dynamo (setting dynamo=True) can capture conditional execution but it also fails on this code with an error:
Could not guard on data-dependent expression Eq(u0, 1) (unhinted: Eq(u0, 1)).
To find out what’s going wrong requires digging deeper into the model.
Isolating the issue
To understand what’s going wrong we need to look into the model code. The first place to look is in the config.json in the nomic-embed-text-v2-moe repository which tells what class is used for AutoModel:
"AutoModel": "nomic-ai/nomic-bert-2048--modeling_hf_nomic_bert.NomicBertModel",This comes from the nomic-bert-2048 repository. As an aside note that this doesn’t pin a revision, so pinning the reivision of nomic-embed-text-v2-moe doesn’t actually protect from malicious code changes because it always pulls in the latest nomic-bert-2048. In any case we can read the modelling code in this repository under modeling_hf_nomic_bert.py.
The onnxruntime error message gives a good hint for where the issue is: /encoder/layers.1/mlp/experts/Expand_1. We can pull this layer out of the model.
experts = model.encoder.layers[1].mlp.expertsAnd look at the forward method that’s being executed.
??experts.forwardSignature: experts.forward( x: torch.Tensor, weights: torch.Tensor, top_weights: torch.Tensor, top_experts: torch.LongTensor, ) -> torch.Tensor Docstring: Define the computation performed at every call. Should be overridden by all subclasses. .. note:: Although the recipe for forward pass needs to be defined within this function, one should call the :class:`Module` instance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them. Source: def forward(self, x: torch.Tensor, weights: torch.Tensor, top_weights: torch.Tensor, top_experts: torch.LongTensor) -> torch.Tensor: bsz, q_len, hidden_size = x.shape x = x.view(-1, hidden_size) out = torch.zeros_like(x) expert_mask = nn.functional.one_hot( top_experts, num_classes=self.moe_num_experts).permute(2, 1, 0) for expert_idx in range(0, self.moe_num_experts): topk_idx, token_idx = torch.where(expert_mask[expert_idx]) if token_idx.shape[0] == 0: continue token_list = token_idx.tolist() topk_list = topk_idx.tolist() expert_tokens = x[None, token_list].reshape(-1, hidden_size) expert_out = self.mlp( expert_tokens, expert_idx) * top_weights[token_list, topk_list, None] out.index_add_(0, token_idx, expert_out) out = out.reshape(bsz, q_len, hidden_size) return out + self.bias File: ~/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/7710840340a098cfb869c4f65e87cf2b1b70caca/modeling_hf_nomic_bert.py Type: method
This might look a bit complicated at first but what’s going on in this Mixture of Experts layer is actually quite straightforward.
Sparse Mixture of Experts
The underlying idea of a Mixture of Experts model is there are multiple subnetworks called “experts” (in this case multilayer perceptrons), and a router network chooses how to weight the outputs from them. In a sparse mixture of experts most of the weights are zero, so we can skip the computation from the non-zero ones. Huggingface have a good blog post on Mixture of Experts that goes into much more detail.
The inputs to this model are the hidden state x, the weights from the router and the top_weights and top_experts selected from the router.
captured_variables = {}
names = [name for name in experts.forward.__annotations__ if name != 'return']
names['x', 'weights', 'top_weights', 'top_experts']Their values can be captured in the model using a Pytorch Hook
hook = None
def capture_input_hook(module, args, output):
for name, value in zip(names, args, strict=True):
captured_variables[name] = value.detach().clone()
captured_variables["return"] = output
# If this cell gets run twice only register the hook once
if hook:
hook.remove()
hook = experts.register_forward_hook(capture_input_hook)Then we can run the model and capture their values:
with torch.inference_mode():
model_output = model(input_ids, attention_mask)
for k,v in captured_variables.items():
print(f"{k:12s}: {str(list(v.shape)):12s} ({v.dtype})")x : [2, 13, 768] (torch.float32)
weights : [26, 8] (torch.float32)
top_weights : [26, 2] (torch.float32)
top_experts : [26, 2] (torch.int64)
return : [2, 13, 768] (torch.float32)With:
- Batch Size:
B - Sequence Length:
L - Embedding Dimension:
D - Number of non-zero experts:
K - Number of Experts:
M
Then the dimensions of the tensors are
- x (hidden state):
B, L, D - weights:
B * L, E - top_weights:
B * L, K - top_experts:
B * L, K - output:
B, L, D
x = captured_variables['x']
weights = captured_variables['weights']
top_weights = captured_variables['top_weights']
top_experts = captured_variables['top_experts']
experts_output = captured_variables['return']Let’s look a bit more closely in at the weights. First capture all the dimensions.
B, L, D = x.shape
K = model.encoder.layers[1].mlp.router.moe_top_k
K2Note that the weights come out of a softmax and sum to one over the experts:
assert torch.allclose(weights.sum(axis=1), torch.ones(B*L))The top weights and top experts are just the values and indices of the largest weights:
topk = torch.topk(weights, k=K)
assert torch.equal(topk.indices, top_experts)
assert torch.equal(topk.values, top_weights)We can realign the top experts and weights to see what they are for each input token:
top_experts_aligned = top_experts.view(B, L, K)
top_weights_aligned = top_weights.view(B, L, K)In this case there are 2 experts, each token has different experts with different weights.
For example the token <s> has experts 0 and 2 with weights 0.80 and 0.14 respectively.
def format_weight(t):
return f'{t.item():0.2f}'
HTML(html_tokens(input_ids[0],
firstExpert = top_experts_aligned[0,:,0],
firstWeight = top_weights_aligned[0,:,0],
secondExpert = top_experts_aligned[0,:,1],
secondWeight = top_weights_aligned[0,:,1],
position=torch.arange(len(input_ids[0])),
formatters=dict(firstWeight=format_weight,
secondWeight=format_weight),
))| Token | <s> | ▁search | _ | que | ry | : | ▁What | ▁food | ▁did | ▁they | ▁eat | ? | </s> |
| ID | 0 | 33938 | 454 | 944 | 1294 | 12 | 4865 | 15381 | 6777 | 1836 | 73203 | 32 | 2 |
| firstExpert | 0 | 1 | 7 | 5 | 6 | 2 | 4 | 1 | 4 | 6 | 1 | 2 | 0 |
| firstWeight | 0.80 | 0.39 | 0.17 | 0.74 | 0.31 | 0.42 | 0.59 | 0.50 | 0.19 | 0.36 | 0.29 | 0.37 | 0.31 |
| secondExpert | 2 | 4 | 3 | 3 | 7 | 6 | 7 | 5 | 1 | 4 | 4 | 7 | 3 |
| secondWeight | 0.14 | 0.27 | 0.16 | 0.07 | 0.24 | 0.19 | 0.10 | 0.20 | 0.16 | 0.17 | 0.26 | 0.18 | 0.15 |
| position | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
Similarly the second element of the batch also has different experts for each token.
HTML(html_tokens(input_ids[1],
firstExpert = top_experts_aligned[1,:,0],
firstWeight = top_weights_aligned[1,:,0],
secondExpert = top_experts_aligned[1,:,1],
secondWeight = top_weights_aligned[1,:,1],
position=torch.arange(len(input_ids[0]), len(input_ids.flatten())),
formatters=dict(firstWeight=format_weight,
secondWeight=format_weight),
))| Token | <s> | ▁search | _ | que | ry | : | ▁thu | nder | storm | s | </s> | <pad> | <pad> |
| ID | 0 | 33938 | 454 | 944 | 1294 | 12 | 4911 | 7944 | 129857 | 7 | 2 | 1 | 1 |
| firstExpert | 0 | 1 | 7 | 5 | 6 | 2 | 3 | 6 | 1 | 7 | 0 | 4 | 4 |
| firstWeight | 0.82 | 0.40 | 0.19 | 0.73 | 0.29 | 0.36 | 0.70 | 0.48 | 0.59 | 0.40 | 0.38 | 0.34 | 0.34 |
| secondExpert | 2 | 4 | 0 | 3 | 7 | 6 | 5 | 1 | 5 | 6 | 4 | 0 | 0 |
| secondWeight | 0.13 | 0.29 | 0.15 | 0.08 | 0.25 | 0.19 | 0.25 | 0.42 | 0.28 | 0.29 | 0.15 | 0.16 | 0.17 |
| position | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 |
The experts layer has an mlp that takes the input and an expert index and outputs the value of that expert.
??experts.mlp.forwardSignature: experts.mlp.forward(x: torch.Tensor, expert_idx: int) -> torch.Tensor Docstring: Define the computation performed at every call. Should be overridden by all subclasses. .. note:: Although the recipe for forward pass needs to be defined within this function, one should call the :class:`Module` instance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them. Source: def forward(self, x: torch.Tensor, expert_idx: int) -> torch.Tensor: expert_w1 = self.w1.view(self.moe_num_experts, self.ffn_hidden_size, self.hidden_size)[expert_idx] expert_w2 = self.w2.view(self.moe_num_experts, self.ffn_hidden_size, self.hidden_size)[expert_idx] x1 = x.matmul(expert_w1.t()) act_out = self.activation_fn(x1) x2 = act_out.matmul(expert_w2) return x2 File: ~/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/7710840340a098cfb869c4f65e87cf2b1b70caca/modeling_hf_nomic_bert.py Type: method
The straight-forward way to calculate the output of the mixture of experts is to loop over every element of the batch, sequence length, and top-k tokens and pass the corresponding hidden state through the appropripriate expert index, and multiply by the weight:
with torch.inference_mode():
result = torch.zeros_like(x)
for b in range(B):
for l in range(L):
for k in range(K):
result[b,l] += (
experts.mlp(x[b,l],
top_experts_aligned[b, l, k])
* top_weights_aligned[b, l, k]
)
assert torch.allclose(result + experts.bias, experts_output, atol=1e-3)How Nomic MoE calculates
In the Nomic Mixture of Experts layer there are some tricks to make it run faster than this naive loop. There’s a specialised implementation called Megablocks that run much faster on a GPU, and Nomic have a version forked from the Databricks implementation; however this is Triton code that doesn’t export easily and is harder to debug.
They’ve got a fallback implementation that we will look at that tries to do all the calculation for a single expert at once, to reduce the amount of memory movement loading the expert weights.
To start make a mask that has 1 in [i, j, k] if i = top_experts[k,j] and 0 otherwise:
from torch import nn
expert_mask = (
nn.functional.one_hot(
top_experts,
num_classes=experts.moe_num_experts)
.permute(2, 1, 0)
)
expert_mask.shapetorch.Size([8, 2, 26])This can be used to find all tokens across the batch and sequence length that use a given expert.
For example for expert_idx = 0 it’s the first expert for tokens 0, 12, 13, and 23 (wrapping around; so token 13 is actually token 0 for batch item 1) and the second expert for tokens 15, 24, and 25.
expert_idx = 0
topk_idx, token_idx = torch.where(expert_mask[expert_idx])
token_list = token_idx.tolist()
topk_list = topk_idx.tolist()
topk_list, token_list([0, 0, 0, 0, 1, 1, 1], [0, 12, 13, 23, 15, 24, 25])We then pluck out the corresponding components of x
expert_tokens = x.view(-1, D)[None, token_list].reshape(-1, D)
expert_tokens.shapetorch.Size([7, 768])Then run all of these through the expert:
expert_out = (
experts.mlp(expert_tokens, expert_idx)
* top_weights[token_list, topk_list, None]SyntaxError: incomplete input (793253010.py, line 3)The nomic implementation does this for each expert, with some special logic to skip the computation if the expert isn’t used for any token.
Exporting Nomic MoE to ONNX
So now it’s a bit easier to see what’s going wrong with the ONNX export: the shape of topk_list and token_list will change each iteration, but PyTorch’s JIT Tracing can’t capture that dynamic execution, and in particular when we run tolist() it just captures the values from the original input.
torch.onnx.export(experts,
(x, weights, top_weights, top_experts),
model_dir / 'experts.onnx',
input_names = ['x', 'weights', 'top_weights', 'top_experts'],
dynamic_axes = {'x': {0: 'batch', 1: 'sequence_length', 2: 'hidden'},
'weights': {0: 'batch_sequence_lengh', 1: 'num_experts'},
'top_weights': {0: 'batch_sequence_lengh', 1: 'top_k'},
'top_experts': {0: 'batch_sequence_lengh', 1: 'top_k'},
},
dynamo=False,
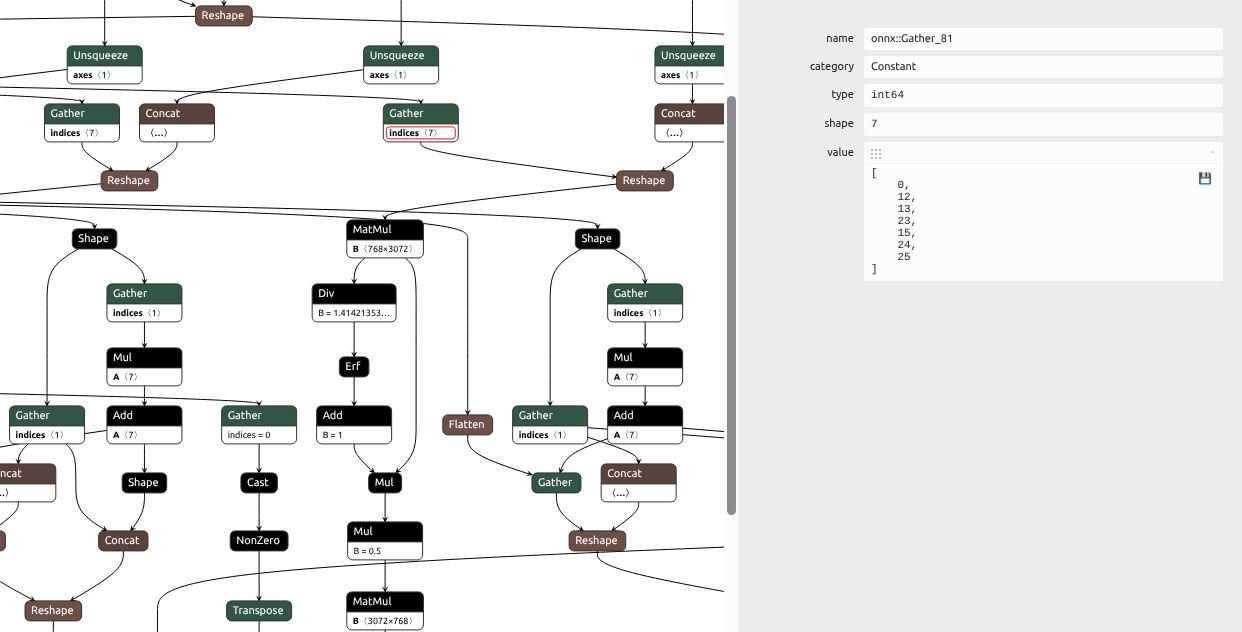
)This can be seen directly looking into the model here’s a screenshot from netron where we can see the token list [0, 12, 13, 23, 15, 24, 25] from this particular input is hard-coded into the model. This means it won’t work correctly on other inputs!
Unconditional Mixture of Experts
The Mixture of Experts doesn’t need any conditional control flow if we do some extra redundant computation. If we just run all the tokens through all the experts and multiply all but the top-k experts by zero we get the same result.
E = 8 # Number of experts
with torch.inference_mode():
# Get the output for every expert
# Shape: B, L, E, D
mlp_output = torch.stack([experts.mlp(x, expert_idx)
for expert_idx
in range(experts.moe_num_experts)],
dim=-2)
# Get the weight matrix with only the values of the top_weights
# at the indices of top_experts, and zeros elsewhere
# (This is the same as masking all non-top weights with 0)
# B, L, E, 1
weight_mask = (
torch.scatter(torch.zeros_like(weights),
1, top_experts, top_weights)
.view(B, L, E)
.unsqueeze(-1)
)
# Calculate the weighted sum; a lot of these multiplcations are zero
result = (mlp_output * weight_mask).sum(dim=-2) + experts.bias
assert torch.allclose(result, experts_output, atol=1e-5)At first this seems really bad from a performance perspective; we’re doing a bunch of extra computation that’s going to waste. But it depends whether the computation is compute bound or memory bound; since we’re running the experts serially it has reasonable data locality. There are other ways to do this - but let’s first see whether this approach even works.
Putting the computation in a Module
Now let’s create an ExportableNomicExpert module that takes an existing NomicExpert layer and replaces the forward method with the computation above
class ExportableNomicExpert(nn.Module):
def __init__(self, other):
super().__init__()
self.moe_num_experts = other.moe_num_experts
self.mlp = other.mlp
self.bias = other.bias
def forward(self, x, weights, top_weights, top_experts):
bsz, q_len, hidden_size = x.shape
weight_mask = (
torch.scatter(torch.zeros_like(weights),
1, top_experts, top_weights)
.view(bsz, q_len, self.moe_num_experts)
.unsqueeze(-1)
)
mlp_output = torch.stack(
[self.mlp(x, expert_idx)
for expert_idx
in range(self.moe_num_experts)],
dim=-2)
out = (mlp_output * weight_mask).sum(dim=-2)
out = out.reshape(bsz, q_len, hidden_size)
return out + self.biasChecking this
with torch.inference_mode():
layer_output = experts(x, weights, top_weights, top_experts)
exportable_experts = ExportableNomicExpert(experts)
with torch.inference_mode():
exportable_layer_output = exportable_experts(x, weights, top_weights, top_experts)
assert torch.allclose(layer_output, exportable_layer_output, atol=1e-6)Monkey patching the model
Now there’s a solution for making the experts layer exportable we should replace every NomicExperts layer with a ExportableNomicExperts layer.
We will use a fresh copy of the model to modify for exporting:
export_model = AutoModel.from_pretrained(model_name,
trust_remote_code=True,
revision=revision)
for layer in export_model.encoder.layers:
if type(layer.mlp).__name__ == 'NomicMoELayer':
layer.mlp.experts = ExportableNomicExpert(layer.mlp.experts)ONNX Export
Now we’ll try to export the model once more.
os.unlink(onnx_path)
torch.onnx.export(export_model.eval(),
(input_ids, attention_mask),
onnx_path,
input_names = ['input_ids', 'attention_mask'],
dynamic_axes = {'input_ids': {0: 'batch', 1: 'sequence_length'},
'attention_mask': {0: 'batch', 1: 'sequence_length'},
},
dynamo=False,
)When the model is loaded:
ort_session = onnxruntime.InferenceSession(
onnx_path, providers=["CPUExecutionProvider"]
)It gets a similar result to the original model:
tokens = tokenizer(['search_query: weather'])
output = ort_session.run(None, {
"input_ids": tokens['input_ids'],
"attention_mask": tokens['attention_mask']}
)[0]
with torch.inference_mode():
expected = model(**{k:torch.tensor(v)
for k,v in tokens.items()}).last_hidden_stateThe model has been successfully exported!
What we didn’t look at
There are a few more things I haven’t done here that would be part of a more production complete solution.
Putting the pooling layer into ONNX
For most applications we don’t want the individual token embeddings, but just the mean pooled and normalised embeddings. Ideally this would be in the ONNX model so that logic doesn’t need to be implemented in the calling code. This can be done by wrapping the module in a similar way to how SentenceTransformers does before exporting.
Conditional computation in RoPE
When the model is exported there are warnings even after patching the Mixture of Experts model (which are not visible above due to how Python suppresses multiple occurrences of the same warning). This is because there is caching of the computation of the RoPE matrices to the maximum length seen. If the model is exported before running any inference (as we did above) then PyTorch JIT will capture the cache needs to be recalculated each time and you will always get the correct result. However if the model is called before export, and when is exported uses that cache, then it will always use that cache and there will be errors in ONNX inference if it’s called on an input larger than the cached length.
This is easily monkey patched in a similar way to the NomicExpert models by removing all caching (or alternatively building a fixed maximum size cache).
Torch Dynamo Export
The TorchScript JIT export we used is going to eventually deprecated and replaced with Torch Dynamo. Torch Dynamo is much more flexible and safer - it refuses to export the original malfunctioning model we had (with a very opaque error message). After replacing the Experts and RoPE layers the model can be exported with Torch Dynamo.
Conditional Computation in ONNX
Torch Dynamo also let’s us use some conditional computation in ONNX. ONNX has an If operator that can take a boolean condition and then execute a different branch depending on that condition. PyTorch allows using this, in a restricted setting using torch.cond and has a good tutorial on this. This could potentially be used to only execute some of the experts; for example if the expert is selected we calculate the MLP otherwise we return a tensor of zeros.
What impact this, or any other changes to how the mixture of experts calculation, have on the speed of inference needs to be benchmarked in ONNX.
Conclusion
PyTorch makes exporting many models to ONNX very simple, but when they use a lot of Python logic it can be quite difficult. The best approach is to disect the model and find the layers that are preventing the export and then replace them with layers that can be exported. If you’re exporting with the TorchScript JIT (dynamo=false) then read the warnings carefully and test the ONNX model gives the correct result against a wide range of inputs.